Have you ever wondered how companies predict customer behavior, forecast sales, or detect fraudulent activities before they even happen? Predictive analytics holds the key to unlocking these insights and more. In today’s data-driven world, organizations are harnessing the power of predictive analytics to gain a competitive edge, make informed decisions, and drive business growth.
From analyzing historical data to forecasting future trends, predictive analytics leverages advanced statistical algorithms and machine learning techniques to uncover patterns, relationships, and insights hidden within vast datasets. By understanding the fundamentals of predictive analytics, exploring various modeling techniques, and mastering deployment strategies, you can unlock the full potential of data-driven decision-making and transform your organization’s operations.
In this guide, we’ll delve into predictive analytics, its importance across industries, real-world applications, evolving trends, and best practices for successful implementation. Whether you’re a business leader looking to leverage predictive insights or a data scientist aiming to enhance your modeling skills, this guide will equip you with the knowledge and tools to navigate the exciting world of predictive analytics effectively.
What is Predictive Analytics?
Predictive analytics is a branch of advanced analytics that utilizes historical data, statistical algorithms, and machine learning techniques to forecast future events or behaviors. It involves extracting insights from past data to predict future outcomes and make informed decisions.
Predictive analytics leverages various statistical and machine learning models to analyze patterns and relationships in data, identify trends, and make predictions about future events. By analyzing historical data and identifying patterns, organizations can anticipate future trends, mitigate risks, and capitalize on opportunities.
Importance of Predictive Analytics
- Enhanced Decision Making: Predictive analytics provides organizations with valuable insights and foresight into future trends, enabling them to make data-driven decisions with confidence. By leveraging predictive models, organizations can optimize operations, allocate resources effectively, and mitigate risks.
- Improved Customer Experience: Predictive analytics enables organizations to anticipate customer needs, preferences, and behaviors, allowing them to personalize marketing campaigns, product recommendations, and customer interactions. By delivering relevant and timely offerings, organizations can enhance customer satisfaction and loyalty.
- Risk Mitigation: Predictive analytics helps organizations identify and mitigate risks by predicting potential outcomes and assessing their likelihood and impact. Whether it’s identifying fraudulent activities, assessing credit risks, or predicting equipment failures, predictive models enable proactive risk management strategies.
- Operational Efficiency: Predictive analytics enables organizations to optimize processes, streamline operations, and improve resource allocation. By predicting demand, optimizing supply chains, and forecasting inventory levels, organizations can reduce costs, minimize waste, and improve operational efficiency.
- Innovation and Competitive Advantage: Predictive analytics empowers organizations to innovate, adapt, and stay ahead of the competition in today’s dynamic business environment. By leveraging predictive insights, organizations can identify emerging trends, seize new opportunities, and differentiate themselves in the market.
Predictive Analytics Applications
- Marketing and Sales: Predictive analytics is widely used in marketing and sales to identify and target high-value customers, optimize marketing campaigns, and forecast sales and demand. By analyzing customer behavior, preferences, and demographics, organizations can personalize marketing efforts and increase conversion rates.
- Finance and Banking: In finance and banking, predictive analytics is used for credit scoring, fraud detection, risk management, and portfolio optimization. By analyzing historical transaction data and customer profiles, financial institutions can assess creditworthiness, detect suspicious activities, and minimize financial risks.
- Healthcare: Predictive analytics plays a critical role in healthcare for patient risk stratification, disease prediction, treatment optimization, and resource allocation. By analyzing electronic health records, medical imaging data, and genomic data, healthcare providers can identify at-risk patients, personalize treatment plans, and improve patient outcomes.
- Manufacturing and Supply Chain: In manufacturing and supply chain management, predictive analytics is used for demand forecasting, predictive maintenance, inventory optimization, and quality control. By analyzing production data, sensor data, and supply chain metrics, organizations can optimize production schedules, reduce downtime, and minimize disruptions.
- Human Resources: Predictive analytics is increasingly being used in human resources for talent acquisition, workforce planning, employee retention, and performance management. By analyzing employee data, recruitment metrics, and engagement surveys, organizations can identify top performers, predict turnover, and optimize workforce strategies.
Predictive Analytics Evolution and Current Trends
Predictive analytics has evolved significantly over the years, driven by advances in technology, data availability, and analytical techniques. Some current trends shaping the field of predictive analytics include:
- Big Data and AI: The proliferation of big data and advancements in artificial intelligence (AI) and machine learning have expanded the scope and capabilities of predictive analytics. Organizations can now analyze large volumes of structured and unstructured data to uncover hidden patterns and insights.
- Real-Time Analytics: There is a growing demand for real-time predictive analytics capabilities to enable organizations to make timely decisions and respond quickly to changing market conditions. Real-time analytics allows organizations to monitor and analyze data streams in real-time, enabling proactive decision-making and intervention.
- Explainable AI: As AI and machine learning models become more complex, there is increasing emphasis on making these models explainable and interpretable. Explainable AI techniques enable organizations to understand how predictive models arrive at their decisions, increasing transparency and trust.
- Automated Machine Learning (AutoML): Automated machine learning platforms and tools are democratizing predictive analytics by making it easier for non-experts to build and deploy predictive models. AutoML platforms automate the model selection, feature engineering, and hyperparameter tuning process, enabling organizations to accelerate model development and deployment.
- Ethical AI and Responsible Data Use: With the growing use of predictive analytics, there is heightened awareness of ethical considerations and responsible data use. Organizations are increasingly focusing on fairness, transparency, and accountability in predictive analytics initiatives to mitigate biases and ensure ethical use of data and technology.
Fundamentals of Predictive Analytics
Predictive analytics starts with the collection and preprocessing of data, followed by exploratory data analysis (EDA), feature engineering, and model selection. Let’s delve into each of these fundamental aspects to understand how they contribute to the predictive analytics process.
Data Collection and Preprocessing
Data collection is the foundation of any predictive analytics project. It involves gathering relevant data from various sources, such as databases, APIs, sensors, and social media platforms. However, raw data often contains errors, missing values, and inconsistencies that need to be addressed before analysis. This is where data preprocessing comes in.
Data preprocessing encompasses several steps, including data cleaning, integration, transformation, and reduction:
- Data Cleaning: Identifying and rectifying errors, inconsistencies, and outliers in the dataset. This may involve removing duplicates, correcting typos, and handling missing values.
- Data Integration: Combining data from multiple sources into a unified dataset. This ensures that all relevant information is available for analysis.
- Data Transformation: Converting raw data into a suitable format for analysis. This may involve scaling numerical features, encoding categorical variables, and creating derived features.
- Data Reduction: Reducing the dimensionality of the dataset to improve computational efficiency and mitigate the curse of dimensionality. Techniques such as principal component analysis (PCA) and feature selection help identify the most important variables for modeling.
Exploratory Data Analysis (EDA)
EDA is a crucial step in the predictive analytics process as it allows us to gain insights into the underlying structure of the data. By visualizing and summarizing the data, we can identify patterns, trends, and relationships that may inform subsequent modeling decisions.
Common techniques used in EDA include:
- Descriptive Statistics: Calculating summary statistics such as mean, median, standard deviation, and percentiles to describe the central tendency and dispersion of the data.
- Data Visualization: Creating plots and charts, such as histograms, scatter plots, and box plots, to visualize the distribution of variables and identify outliers.
- Correlation Analysis: Examining the correlation between variables to identify potential relationships and dependencies. This helps determine which variables are likely to be predictive of the target variable.
EDA not only helps us understand the data better but also guides feature selection, model selection, and interpretation of results.
Feature Engineering
Feature engineering is the process of creating new features or transforming existing ones to improve the performance of predictive models. While the success of predictive modeling depends on various factors such as algorithm choice and model tuning, the quality of features plays a crucial role in determining predictive accuracy.
Some common techniques used in feature engineering include:
- Feature Scaling: Scaling numerical features to a similar range to prevent certain features from dominating others in the model. Common scaling methods include standardization (mean normalization) and normalization (min-max scaling).
- Feature Encoding: Converting categorical variables into numerical representations that can be used in predictive models. One-hot encoding, label encoding, and ordinal encoding are common techniques used for feature encoding.
- Feature Selection: Identifying the most relevant features that contribute to the predictive power of the model while reducing dimensionality and computational complexity. Techniques such as forward selection, backward elimination, and recursive feature elimination help select the optimal subset of features.
Feature engineering requires domain knowledge and creativity to extract meaningful information from raw data and transform it into predictive features that capture the underlying patterns in the data.
Model Selection
Model selection involves choosing the most appropriate algorithm or combination of algorithms to build predictive models that generalize well to unseen data. The choice of model depends on various factors, including the nature of the problem, the size and complexity of the dataset, and the interpretability of the model.
Common types of predictive models include:
- Linear Models: Linear regression for regression tasks and logistic regression for classification tasks. These models are simple, interpretable, and well-suited for linearly separable data.
- Tree-Based Models: Decision trees, random forests, and gradient boosting machines (GBM) are popular ensemble methods that combine multiple decision trees to improve predictive performance and handle nonlinear relationships in the data.
- Neural Networks: Deep learning models such as artificial neural networks (ANNs) and convolutional neural networks (CNNs) are powerful tools for modeling complex, high-dimensional data but require large amounts of data and computational resources.
Model selection involves evaluating the performance of different algorithms using metrics such as accuracy, precision, recall, F1-score, and area under the receiver operating characteristic (ROC) curve. Cross-validation techniques such as k-fold cross-validation help assess the generalization performance of the models and identify potential sources of overfitting or underfitting.
Choosing the right model requires a balance between model complexity, predictive performance, interpretability, and computational efficiency. Experimentation and iteration are key to finding the optimal model for a given predictive analytics task.
Data Preparation for Predictive Analytics
Preparing data for predictive analytics is a crucial step that ensures the accuracy and reliability of predictive models. We’ll explore the various techniques and processes involved in data preparation, including data cleaning, handling missing values, encoding categorical variables, and feature scaling and normalization.
Data Cleaning and Transformation
Data cleaning and transformation are essential tasks to ensure the quality and consistency of the dataset before analysis. This involves identifying and rectifying errors, inconsistencies, and outliers that may affect the performance of predictive models.
Data Cleaning Techniques:
- Removing Duplicates: Identifying and removing duplicate records from the dataset to prevent redundancy and bias in the analysis.
- Correcting Errors: Identifying and correcting errors in the data, such as typos, formatting inconsistencies, and outliers that may skew the results.
- Handling Outliers: Identifying outliers that deviate significantly from the rest of the data distribution and deciding whether to remove, transform, or impute them based on domain knowledge.
Data Transformation Techniques:
- Normalization: Scaling numerical features to a similar range to prevent certain features from dominating others in the model. This is particularly important for distance-based algorithms such as K-nearest neighbors (KNN) and support vector machines (SVM).
- Log Transformation: Applying logarithmic transformation to skewed or heavily skewed variables to make their distribution more symmetric and improve model performance.
- Binning/Bucketing: Grouping continuous variables into discrete bins or categories to simplify the data and capture non-linear relationships.
Handling Missing Values
Missing values are a common issue in real-world datasets and need to be addressed before building predictive models. Failure to handle missing values appropriately can lead to biased or inaccurate predictions.
Strategies for Handling Missing Values:
- Imputation: Filling missing values with a suitable estimate, such as the mean, median, or mode of the feature. Imputation methods include mean imputation, median imputation, and regression imputation.
- Deletion: Removing rows or columns with missing values if they constitute a small proportion of the data or are unrelated to the analysis. However, this approach may lead to loss of valuable information.
- Prediction: Using predictive models such as linear regression, decision trees, or K-nearest neighbors to estimate missing values based on other features in the dataset.
Encoding Categorical Variables
Categorical variables need to be encoded into numerical representations before they can be used in predictive models. This is necessary because most machine learning algorithms require numerical inputs.
Common Encoding Techniques:
- One-Hot Encoding: Creating binary dummy variables for each category of the categorical variable. This creates a binary feature for each category, where 1 indicates the presence of the category and 0 indicates absence.
- Label Encoding: Assigning numerical labels to categories, usually in alphabetical order or based on their frequency. This is suitable for ordinal categorical variables where the order of categories is meaningful.
- Ordinal Encoding: Mapping categories to numerical values based on their order or significance. This is suitable for ordinal categorical variables where the categories have a natural order.
Feature Scaling and Normalization
Feature scaling and normalization ensure that numerical features have a similar scale, preventing certain features from dominating others in the model and improving convergence rates for gradient-based optimization algorithms.
Common Scaling Techniques:
- Standardization: Scaling features to have a mean of 0 and a standard deviation of 1. This ensures that the features have a similar scale and allows algorithms to converge faster.
- Normalization: Scaling features to a range between 0 and 1. This is achieved by subtracting the minimum value and dividing by the range of the feature.
By preprocessing the data effectively, we can ensure that predictive models are trained on clean, reliable data, leading to more accurate predictions and actionable insights.
Predictive Modeling Techniques
Predictive modeling techniques are the heart of predictive analytics, allowing us to build models that can make accurate predictions based on historical data.
Regression Analysis
Regression analysis is used when the target variable is continuous, and we want to predict its value based on one or more independent variables. It is widely used in fields such as economics, finance, and healthcare for forecasting and modeling relationships between variables.
Types of Regression Analysis:
- Linear Regression: Linear regression models the relationship between the target variable and independent variables using a linear equation. The coefficients of the equation represent the effect of each independent variable on the target variable.
- Polynomial Regression: Polynomial regression extends linear regression by fitting a polynomial function to the data, allowing for more complex relationships between variables.
- Ridge Regression: Ridge regression is a regularization technique that adds a penalty term to the loss function to prevent overfitting by shrinking the coefficients towards zero.
- Lasso Regression: Lasso regression is another regularization technique that penalizes the absolute size of the coefficients, leading to sparse models with fewer features.
Classification Methods
Classification methods are used when the target variable is categorical, and we want to classify observations into predefined classes or categories. Classification is widely used in areas such as healthcare, marketing, and fraud detection for identifying patterns and making predictions.
Common Classification Algorithms:
- Logistic Regression: Logistic regression is a binary classification algorithm that models the probability of a binary outcome using a logistic function. It is widely used for binary classification tasks such as spam detection and credit scoring.
- Decision Trees: Decision trees partition the feature space into hierarchical segments based on the value of features, allowing for nonlinear relationships between variables. They are easy to interpret and visualize, making them suitable for exploratory analysis.
- Random Forests: Random forests are an ensemble learning technique that combines multiple decision trees to improve predictive performance and reduce overfitting. They are robust to noise and outliers and can handle high-dimensional data.
- Support Vector Machines (SVM): SVM is a powerful classification algorithm that finds the optimal hyperplane that separates different classes in the feature space. It is effective for both linear and nonlinear classification tasks.
Time Series Forecasting
Time series forecasting involves predicting future values of a time-dependent variable based on historical data points. It is widely used in fields such as finance, retail, and energy for forecasting sales, stock prices, and demand.
Techniques for Time Series Forecasting:
- ARIMA (AutoRegressive Integrated Moving Average): ARIMA is a popular time series forecasting technique that models the future values of a series as a linear combination of its past values and lagged forecast errors.
- Exponential Smoothing: Exponential smoothing is a family of forecasting methods that assigns exponentially decreasing weights to past observations. It is suitable for time series data with trend and seasonality.
- Prophet: Prophet is a forecasting tool developed by Facebook that models time series data with trend, seasonality, and holiday effects. It is easy to use and can handle missing data and outliers.
Ensemble Methods
Ensemble methods combine multiple base models to improve predictive performance and reduce overfitting. They are widely used in machine learning competitions and real-world applications for achieving state-of-the-art performance.
Types of Ensemble Methods:
- Bagging (Bootstrap Aggregating): Bagging involves training multiple base models on different subsets of the training data and averaging their predictions to reduce variance and improve robustness.
- Boosting: Boosting algorithms sequentially train base models, where each subsequent model focuses on correcting the errors of its predecessors. Popular boosting algorithms include AdaBoost, Gradient Boosting Machines (GBM), and XGBoost.
- Stacking: Stacking combines predictions from multiple base models using a meta-model, often a simple linear regression or a neural network. It leverages the strengths of individual models to improve overall performance.
Deep Learning Approaches
Deep learning approaches use artificial neural networks with multiple layers to model complex patterns and relationships in data. They have achieved remarkable success in fields such as computer vision, natural language processing, and speech recognition.
Common Deep Learning Architectures:
- Feedforward Neural Networks: Feedforward neural networks consist of multiple layers of interconnected neurons, where information flows in one direction from input to output. They are suitable for a wide range of applications but may suffer from overfitting with large, high-dimensional datasets.
- Convolutional Neural Networks (CNNs): CNNs are specialized neural networks designed for processing grid-like data such as images. They use convolutional layers to extract features from input images and pooling layers to reduce spatial dimensions.
- Recurrent Neural Networks (RNNs): RNNs are designed to model sequential data with temporal dependencies. They have recurrent connections that allow them to capture long-term dependencies in time series data, text, and speech.
- Long Short-Term Memory (LSTM) Networks: LSTMs are a type of RNN that are capable of learning long-term dependencies and are particularly effective for time series forecasting and natural language processing tasks.
By leveraging these predictive modeling techniques, organizations can extract valuable insights from data, make informed decisions, and gain a competitive advantage in today’s data-driven world. Each technique has its strengths and limitations, and the choice of technique depends on the nature of the problem, the characteristics of the data, and the specific requirements of the application. Experimentation and iteration are key to finding the most effective approach for a given predictive analytics task.
Predictive Model Evaluation and Validation
Once predictive models are built, it’s crucial to assess their performance and ensure they generalize well to unseen data. In this section, we’ll explore various techniques for model evaluation and validation.
Cross-Validation Techniques
Cross-validation is a robust technique used to assess the performance of predictive models by partitioning the dataset into multiple subsets, training the model on different subsets, and evaluating its performance on the remaining subsets. This helps estimate how well the model will generalize to unseen data.
Common Cross-Validation Techniques:
- K-Fold Cross-Validation: In K-fold cross-validation, the dataset is divided into K equal-sized folds. The model is trained K times, each time using K-1 folds for training and the remaining fold for validation. The performance metrics are averaged across all K folds to obtain the final evaluation score.
- Stratified K-Fold Cross-Validation: Stratified K-fold cross-validation ensures that each fold contains a proportional representation of each class in the dataset. This is particularly useful for imbalanced datasets where certain classes are underrepresented.
- Leave-One-Out Cross-Validation (LOOCV): In LOOCV, a single observation is held out as the validation set, and the model is trained on the remaining data. This process is repeated for each observation in the dataset, resulting in N iterations for a dataset with N observations.
Performance Metrics
Performance metrics are used to quantify the performance of predictive models and compare different models based on their predictive accuracy, precision, recall, and other relevant criteria. The choice of performance metric depends on the nature of the problem and the specific requirements of the application.
Common Performance Metrics:
- Accuracy: Accuracy measures the proportion of correctly classified instances out of all instances in the dataset. While accuracy is a useful metric for balanced datasets, it may be misleading for imbalanced datasets where the classes are unevenly distributed.
- Precision: Precision measures the proportion of true positive predictions out of all positive predictions made by the model. It focuses on the accuracy of positive predictions and is particularly important in scenarios where false positives are costly.
- Recall (Sensitivity): Recall measures the proportion of true positive predictions out of all actual positive instances in the dataset. It focuses on the ability of the model to correctly identify positive instances and is important in scenarios where false negatives are costly.
- F1-Score: The F1-score is the harmonic mean of precision and recall, providing a balance between the two metrics. It is a useful metric for imbalanced datasets where both false positives and false negatives need to be minimized.
Overfitting and Underfitting
Overfitting and underfitting are common challenges in predictive modeling, where the model either captures noise and irrelevant patterns in the training data (overfitting) or fails to capture the underlying patterns in the data (underfitting).
Overfitting:
Overfitting occurs when the model learns the training data too well, capturing noise and random fluctuations that are not present in the underlying data distribution. This leads to poor generalization performance on unseen data.
Underfitting:
Underfitting occurs when the model is too simple to capture the underlying patterns in the data, resulting in high bias and poor predictive performance. Underfit models fail to capture the complexity of the data and perform poorly on both training and test data.
Hyperparameter Tuning
Hyperparameter tuning involves optimizing the hyperparameters of predictive models to improve their performance and generalization ability. Hyperparameters are configuration settings that control the learning process of the model and are not learned from the data.
Common Hyperparameter Tuning Techniques:
- Grid Search: Grid search involves searching through a predefined grid of hyperparameters and selecting the combination that yields the best performance on the validation set. While grid search is exhaustive and guarantees finding the optimal hyperparameters, it can be computationally expensive for large hyperparameter spaces.
- Random Search: Random search randomly samples hyperparameters from a predefined distribution and evaluates their performance on the validation set. While random search is less computationally expensive than grid search, it may not guarantee finding the optimal hyperparameters.
- Bayesian Optimization: Bayesian optimization uses probabilistic models to model the objective function and guide the search process towards promising regions of the hyperparameter space. It is particularly effective for optimizing expensive-to-evaluate black-box functions.
By employing these model evaluation and validation techniques, we can ensure that predictive models are robust, reliable, and generalize well to unseen data. Experimentation with different techniques and iteration are key to refining and improving the performance of predictive models for various real-world applications.
How to Implement Predictive Models?
Deploying and implementing predictive models is a critical phase in the predictive analytics process, as it involves putting the developed models into practical use within an organization’s operations. Let’s explore the various aspects of deploying and implementing predictive models.
Integration with Business Processes
Successful integration of predictive models with existing business processes is essential for maximizing their impact and value within an organization. This involves aligning predictive analytics initiatives with business objectives, workflows, and decision-making processes.
- Understanding Business Needs: Start by identifying key business problems and challenges that can be addressed with predictive analytics. Engage stakeholders from different departments to understand their requirements and pain points.
- Identifying Use Cases: Once business needs are identified, prioritize use cases where predictive models can add the most value. Consider factors such as potential ROI, data availability, and feasibility of implementation.
- Collaboration with Stakeholders: Collaborate closely with stakeholders, including business analysts, domain experts, and IT professionals, to ensure that predictive models are integrated seamlessly into existing workflows and systems.
- Change Management: Implementing predictive models often requires changes in processes, roles, and responsibilities. Provide training and support to employees to facilitate the adoption of new tools and methodologies.
Model Deployment Strategies
Model deployment involves making predictive models accessible to end-users for making real-time predictions and decisions. It requires careful planning and consideration of factors such as scalability, reliability, and security.
- Cloud Deployment: Deploying predictive models on cloud platforms such as AWS, Azure, or Google Cloud offers scalability, flexibility, and cost-effectiveness. Cloud-based deployment also facilitates collaboration and integration with other cloud-based services.
- On-Premises Deployment: In some cases, organizations may choose to deploy predictive models on their on-premises servers for data privacy, security, or regulatory compliance reasons. On-premises deployment provides greater control over data and infrastructure but may require more upfront investment in hardware and maintenance.
- Containerization: Containerization technologies such as Docker and Kubernetes enable organizations to package predictive models and their dependencies into portable containers that can be deployed consistently across different environments.
Monitoring and Maintenance
Monitoring and maintaining predictive models are essential to ensure their continued effectiveness and relevance over time. This involves tracking model performance, detecting drift, and updating models as needed.
- Performance Monitoring: Monitor key performance metrics such as accuracy, precision, recall, and F1-score to assess the predictive performance of models in real-time. Set up alerts for deviations from expected performance levels.
- Data Drift Detection: Monitor changes in the distribution of input data over time to detect data drift, i.e., when the data used for predictions differs significantly from the data used during model training. Data drift can lead to deterioration in model performance and requires retraining or updating the model.
- Model Drift Detection: Monitor changes in model predictions over time to detect model drift, i.e., when the model’s behavior deviates from its initial performance. Model drift may occur due to changes in the underlying data, shifts in user behavior, or changes in the business environment.
Ethical Considerations
Ethical considerations play a crucial role in the deployment and implementation of predictive models, as they can have significant impacts on individuals, society, and organizations. It’s essential to consider ethical implications related to privacy, fairness, transparency, and accountability.
- Privacy Protection: Ensure that predictive models comply with data protection regulations and respect individuals’ privacy rights. Implement data anonymization, encryption, and access controls to safeguard sensitive information.
- Fairness and Bias Mitigation: Evaluate predictive models for fairness and mitigate biases that may lead to discriminatory outcomes. Implement fairness-aware algorithms, bias detection techniques, and fairness constraints to ensure equitable treatment of different demographic groups.
- Transparency and Explainability: Strive to make predictive models transparent and explainable by providing insights into their decision-making processes. Use interpretable models, feature importance analysis, and model explanations to enhance transparency and trustworthiness.
- Accountability and Governance: Establish clear accountability mechanisms and governance structures for managing predictive analytics initiatives. Document model development processes, decision criteria, and validation procedures to ensure accountability and regulatory compliance.
By addressing these deployment and implementation considerations, organizations can effectively harness the power of predictive analytics to drive business value while upholding ethical standards and promoting responsible use of data and technology.
Predictive Analytics Challenges
Deploying and implementing predictive models can be accompanied by various challenges that organizations need to overcome to ensure successful adoption and utilization. Here are some common challenges:
- Data Quality and Availability: Poor data quality, incomplete data, and data silos can hinder the development and deployment of predictive models. Organizations may struggle to access relevant data or face issues with data inconsistency and accuracy.
- Model Interpretability: Complex predictive models such as deep learning algorithms may lack interpretability, making it difficult for stakeholders to understand and trust the predictions. Ensuring model interpretability is crucial for gaining acceptance and adoption by end-users.
- Scalability and Performance: Scalability issues can arise when deploying predictive models in production environments, particularly for high-volume and real-time applications. Ensuring that models can handle large datasets and maintain acceptable performance is essential for seamless deployment.
- Integration with Existing Systems: Integrating predictive models with existing IT infrastructure and business systems can be challenging, particularly in complex environments with heterogeneous technologies and legacy systems. Compatibility issues, data format mismatches, and security concerns may arise during integration.
- Regulatory Compliance: Predictive models deployed in regulated industries such as healthcare, finance, and insurance must comply with industry-specific regulations and standards. Ensuring regulatory compliance involves addressing data privacy, security, and ethical considerations.
- Model Maintenance and Updates: Predictive models require ongoing maintenance and updates to remain effective and relevant over time. Monitoring model performance, detecting drift, and retraining models with new data are essential for maintaining predictive accuracy and preventing model decay.
Predictive Analytics Best Practices
To overcome the challenges associated with deploying and implementing predictive models, organizations can adopt the following best practices:
- Establish Clear Objectives: Define clear business objectives and use cases for predictive analytics initiatives to ensure alignment with organizational goals and priorities. Focus on high-impact projects with measurable outcomes and ROI.
- Data Governance and Quality Assurance: Implement robust data governance practices to ensure data quality, consistency, and integrity throughout the data lifecycle. Establish data quality assurance processes and invest in data cleansing, validation, and enrichment techniques.
- Collaboration and Communication: Foster collaboration between data scientists, business analysts, domain experts, and IT professionals to leverage diverse expertise and perspectives. Effective communication and collaboration are essential for successful predictive analytics projects.
- Agile Development and Iterative Approach: Adopt agile development methodologies and an iterative approach to model development and deployment. Break down projects into smaller, manageable tasks, and prioritize incremental improvements based on feedback and validation.
- Model Explainability and Transparency: Prioritize model explainability and transparency to enhance understanding and trust among stakeholders. Use interpretable models, visualization techniques, and model explanations to elucidate the decision-making process.
- Continuous Monitoring and Feedback Loop: Implement a continuous monitoring and feedback loop to track model performance, detect anomalies, and gather user feedback. Use monitoring tools, automated alerts, and user surveys to identify issues and opportunities for improvement.
- Invest in Talent and Skills Development: Invest in talent acquisition and skills development to build a team of data scientists, machine learning engineers, and domain experts with the necessary expertise to develop, deploy, and maintain predictive models.
- Ethical and Responsible AI Practices: Prioritize ethical and responsible AI practices to ensure fairness, transparency, and accountability in predictive analytics initiatives. Conduct ethical impact assessments, adhere to ethical guidelines, and engage stakeholders in ethical decision-making processes.
By adopting these best practices, organizations can overcome challenges, maximize the value of predictive analytics, and drive innovation and competitive advantage in today’s data-driven world.
Conclusion
Predictive analytics offers a powerful toolkit for organizations to unlock valuable insights from their data and make informed decisions. By leveraging historical data and advanced modeling techniques, businesses can anticipate future trends, mitigate risks, and identify opportunities for growth. From marketing and sales optimization to healthcare and finance, predictive analytics has wide-ranging applications across industries, driving innovation, and driving competitive advantage.
As organizations continue to embrace data-driven decision-making, it’s essential to prioritize ethical considerations, transparency, and accountability in predictive analytics initiatives. By adhering to best practices, fostering collaboration between stakeholders, and investing in talent and technology, organizations can maximize the value of predictive analytics and drive sustainable success in today’s dynamic business landscape. Whether you’re a business leader, data scientist, or aspiring analyst, the knowledge and insights gained from this guide will empower you to harness the full potential of predictive analytics and drive positive outcomes for your organization.
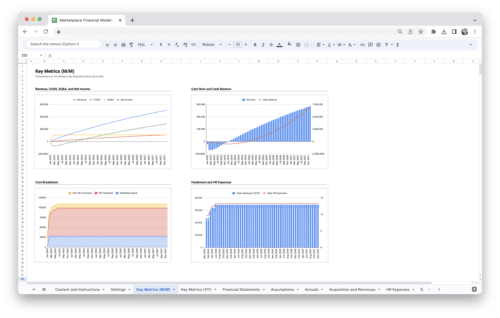
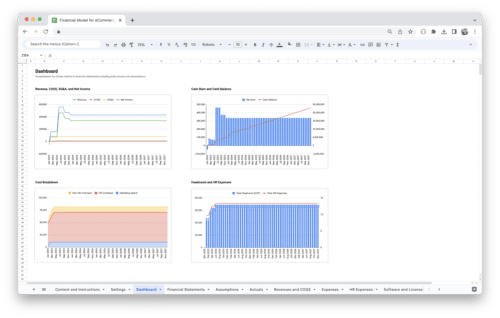
Get Started With a Prebuilt Template!
Looking to streamline your business financial modeling process with a prebuilt customizable template? Say goodbye to the hassle of building a financial model from scratch and get started right away with one of our premium templates.
- Save time with no need to create a financial model from scratch.
- Reduce errors with prebuilt formulas and calculations.
- Customize to your needs by adding/deleting sections and adjusting formulas.
- Automatically calculate key metrics for valuable insights.
- Make informed decisions about your strategy and goals with a clear picture of your business performance and financial health.